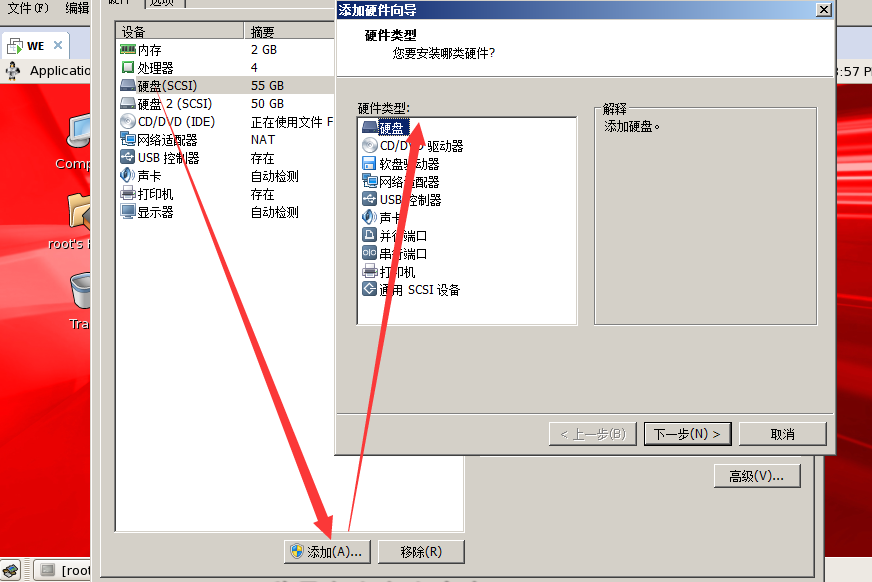
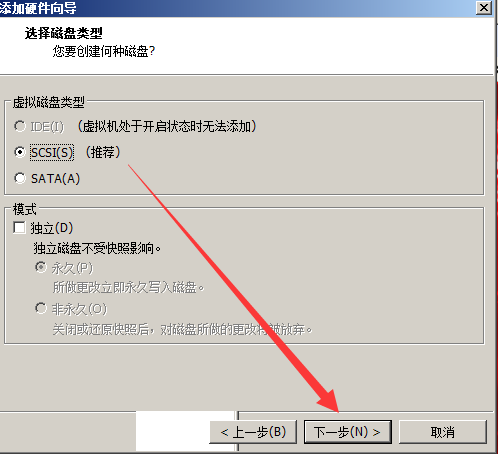
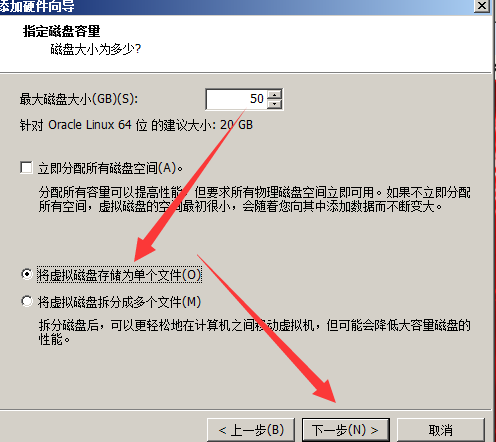
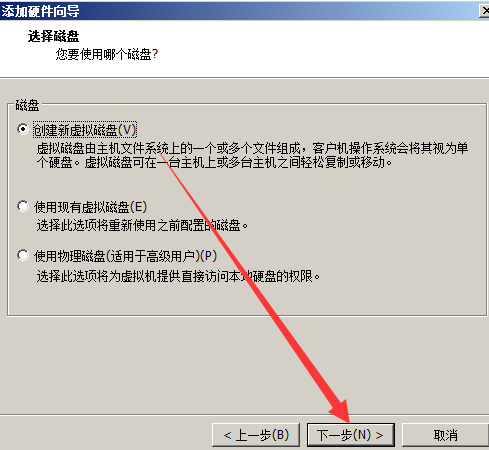
安装包下载链接: https://pan.baidu.com/s/1-HLP6AbAdsy5-v82CBZNIQ 提取码: pkde
GlusterFs离线安装(需在四台机器上操作) 1 2 3 4 5 6 rpm -Uvh xz-libs-5.2.2-1.el7.x86_64.rpm xz-5.2.2-1.el7.x86_64.rpm xz-libs-5.2.2-1.el7.i686.rpm --force --nodeps
启动 Glusterfs 1 2 systemctl start glusterd.serviceenable glusterd.service
添加hosts文件 1 2 3 4 5 [root@localhost ~]
【说明】添加hosts文件这一步不是必需。如果使用IP地址,之后添加节点时也必需使用IP地址。如果使用hosts文件,则4个节点都必需要添加相同的hosts文件
添加GlusterFS集群节点 【说明】本小节操作在任意节点操作即可,且进行操作前要先检查每台机器的防火墙是否关闭。
1 2 3 4 5 6 7 8 [root@gfs129 ~]
【说明】移除节点gluster peer detach gfs132
查看GlusterFS集群状态(任意节点) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@gfs129 ~]in Cluster (Connected)in Cluster (Connected)in Cluster (Connected)
查看GlusterFS volume 1 2 [root@gfs129 ~]
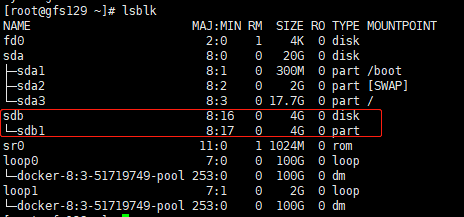
创建Glusterfs所需磁盘 (1)查看磁盘情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@gfs129 ~]in memory only, until you decide to write them.command .for help ): type :type Linux and of size 4 GiB is set for help ): w
执行完后,效果如下图:
1 mkfs.xfs -i size=512 /dev/sdb1
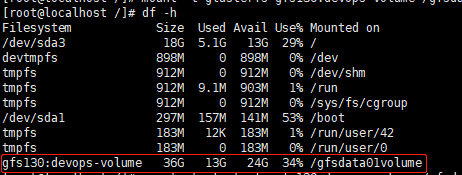
(5)挂载:
1 2 3 4 5 mkdir -p /glusterfs-data/data01/
注意:所有节点都需创建Glusterfs所需磁盘及glusterfs-data数据目录
创建GlusterFS volume(master节点) 分布式复制模式(组合型), 最少需要4台服务器才能创建。创建分布式复制卷需指定卷类型为replica(复制卷)(否则默认为分布式卷),卷类型后边参数是副本数量。Transport指定传输类型为tcp。传输类型后的brick server数量需是副本数量的倍数,且>=2倍。当副本数量与brick server数量不等且符合倍数关系时,即是分布式复制卷
1 2 [root@gfs129 glusterfs-data]
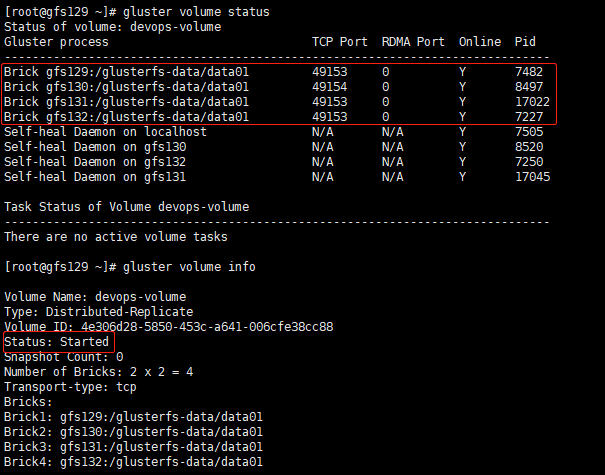
查看GlusterFS volume(任意节点) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@gfs130 ~]type : tcp
启动GlusterFS volume 1 2 [root@gfs129 glusterfs-data]
再次查看GlusterFS volume(任意节点) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@gfs130 /]type : tcp
客户端挂载GlusterFS 如果GlusterFS集群初始化使用了主机/etc/hosts中的信息,请在客户端也添加对应的信息。否则挂载过程会报错。这里就是需要在harbor所在的服务器上把hosts文件添加成跟glusterfs上一致,并且也需要在这台服务器上装一个glusterfs的客户端。安装方式同1中Glusterfs离线安装。
1 2 3 [root@localhost /]
挂载成功后,效果如下:
设置开机自动挂载 1 2 [root@localhost harbor]
Glusterfs的常用命令 参考自 https://blog.csdn.net/lincoln_2012/article/details/52201227
服务器节点 1 2 3 gluster peer status //查看所有节点信息,显示时不包括本节点
glusterd服务 1 2 3 /etc/init.d/glusterd start //启动glusterd服务
创建卷 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 <1>复制卷
启动卷 1 gluster volume start test-volume
停止卷 1 gluster volume stop test-volume
删除卷 1 gluster volume delete test-volume //先停止卷后才能删除
查看卷 1 2 3 4 gluster volume list /*列出集群中的所有卷*/
配置卷 1 gluster volume set <VOLNAME> <OPTION> <PARAMETER>
扩展卷 1 gluster volume add-brick <VOLNAME> <NEW-BRICK>
注意,如果是复制卷或者条带卷,则每次添加的Brick数必须是replica或者stripe的整数倍。
收缩卷 1 2 3 4 5 6 先将数据迁移到其它可用的Brick,迁移结束后才将该Brick移除:
注意,如果是复制卷或者条带卷,则每次移除的Brick数必须是replica或者stripe的整数倍。
迁移卷 1 2 3 4 5 6 7 8 9 10 使用start命令开始进行迁移:
重新均衡卷 添加Brick 删除Brick 1 2 3 4 5 6 7 若是副本卷,则移除的Bricks数是replica的整数倍
替换Brick 任务:把192.168.1.151:/mnt/brick0 替换为192.168.1.151:/mnt/brick2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <1>开始替换
文件系统扩展属性 获取文件扩展属性
1 2 getfattr -d -m . -e hex filename"trusted.afr.*" -e hex filename
日志文件路径 相关日志,在客户端机器的/var/log/glusterfs/目录下,可根据需要查看;
Glusterfs容灾能力研究 glusterfs集群节点关机重启(单节点) 关机的机器没有设置开机自动挂载,关机重启后,挂载点消失 需手动重新挂载
1 mount /dev/sdb1 /glusterfs-data/data01/
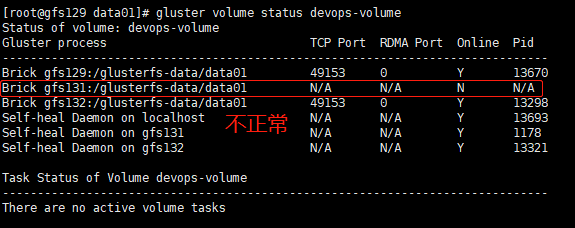
若重新挂载后,出现关机重启后的机器的brick不正常,则在glusterfs集群节点重启数据卷即可:
1 2 gluster volume stop devops-volume
然后重新进入glusterfs目录,发现在关机期间,客户端新建的文件也同步过来了,但是和同一个副本集下的另一个副本的文件扩展属性有差别,如下(关机重启的是gfs131机器):
【说明】
如果gfs131正常,gfs132离线,客户端新往这两台机器写入数据(bcv4.txt),那么,重启gfs132后,该文件的扩展属性与上图1类似,没有trusted.afr.dirty属性值。bcv4.txt的扩展属性在gfs131中与上图2类似,有trusted.afr.dirty属性值且为0x000000000000。 证明此种情况下,gfs131机器的bcv4.txt数据是正常的,gfs132机器的bcv4.txt数据可能是不可靠的。
glusterfs集群节点关机重启(一个副本集下的双节点) 测试关闭了gfs131和gfs132,然后在客户端创建文件
1 touch distributed-replica{1..6}.txt
出现下述问题:
glusterfs集群状态检查 可以通过下述命令,对glusterfs集群进行健康状态的检查: